The next example parser converts JSON strings to JavaScript objects. It
effectively does the same thing as the JSON.parse function. So, it serves
no practical purpose, but is a nice example due to simplicity of the JSON
grammar. To make our implementation marginally more useful, let's allow to
include comments inside JSON.
import * as pz from "..";
First we define all the tokens that JSON files may contain. These are all specified in json.org.
export enum JsonToken {
True, False, Null, LeftBrace, RightBrace, LeftBracket, RightBracket, Comma,
Colon, Number, String, Whitespace, Comment, EOF
}
pz.parserDebug.debugging = false
 We define lexers for all the tokens. First we handle constants and separator
characters. They are trivial to recognize.
We define lexers for all the tokens. First we handle constants and separator
characters. They are trivial to recognize.
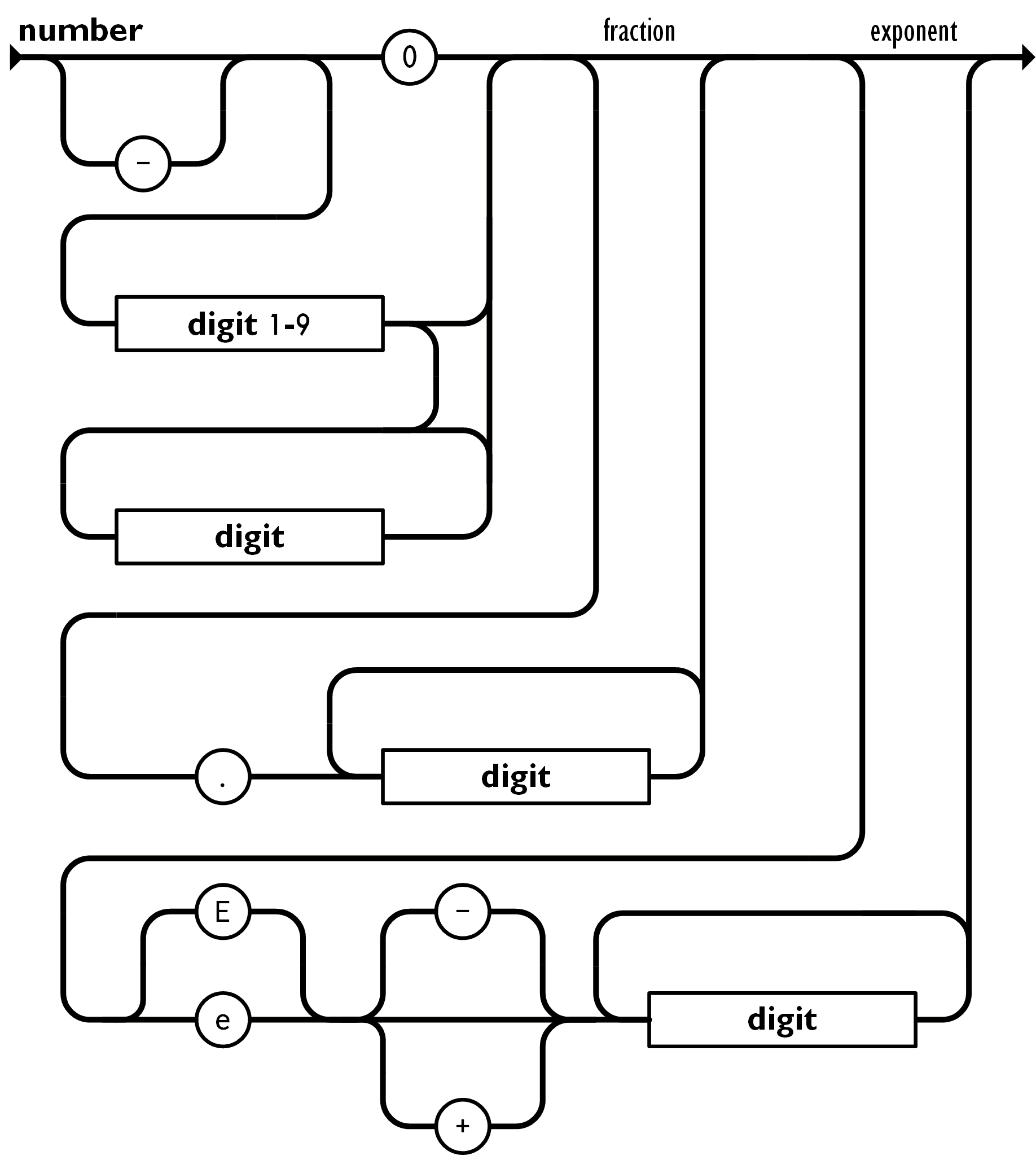
Numbers are a bit trickier as we need to support decimal formats with and without exponents.
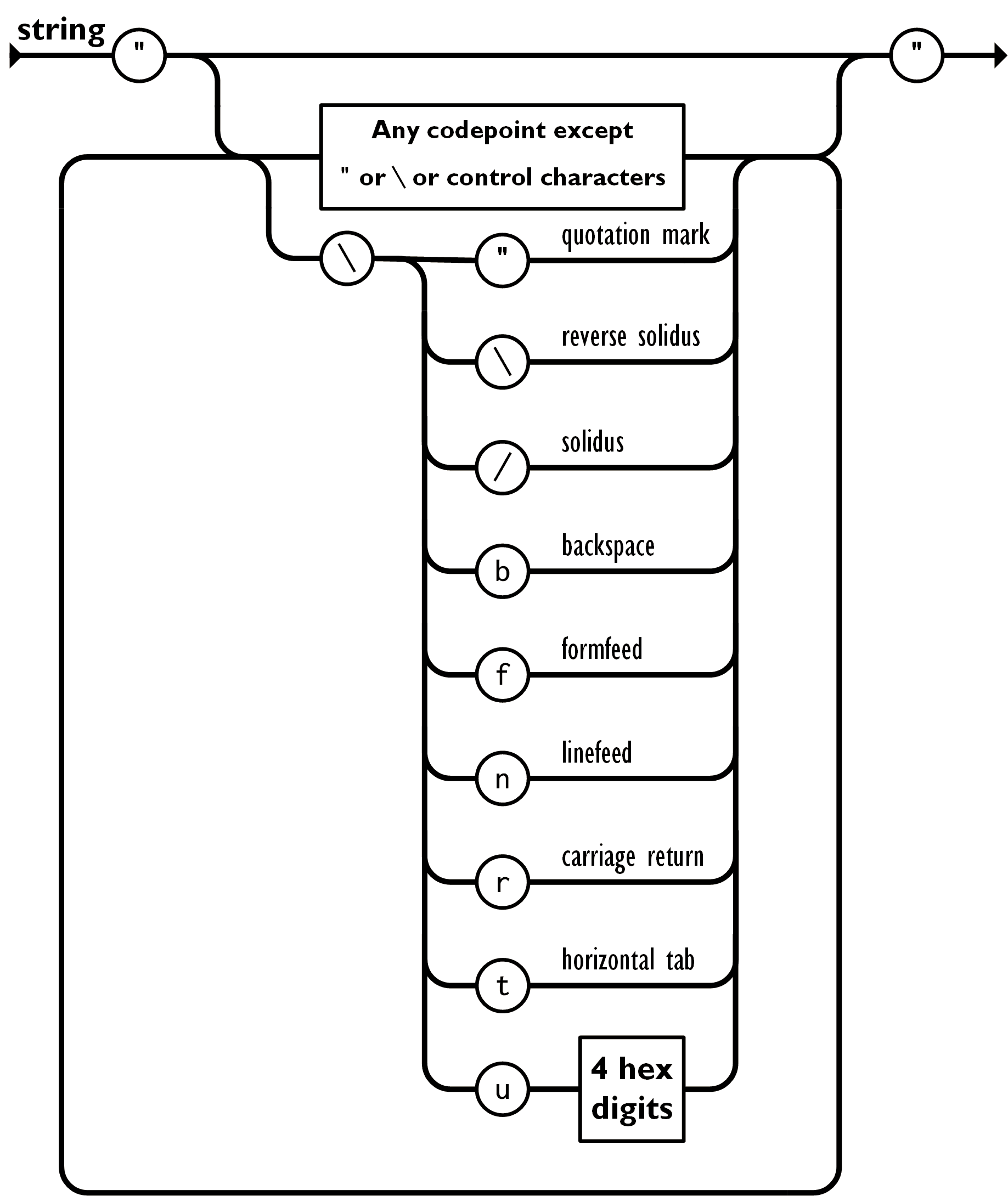 Strings can be a bit tricky as well, as there are special characters that
have to be accounted for. Another notable thing is that we need to use the
Strings can be a bit tricky as well, as there are special characters that
have to be accounted for. Another notable thing is that we need to use the
u specifier in our regex for unicode support.
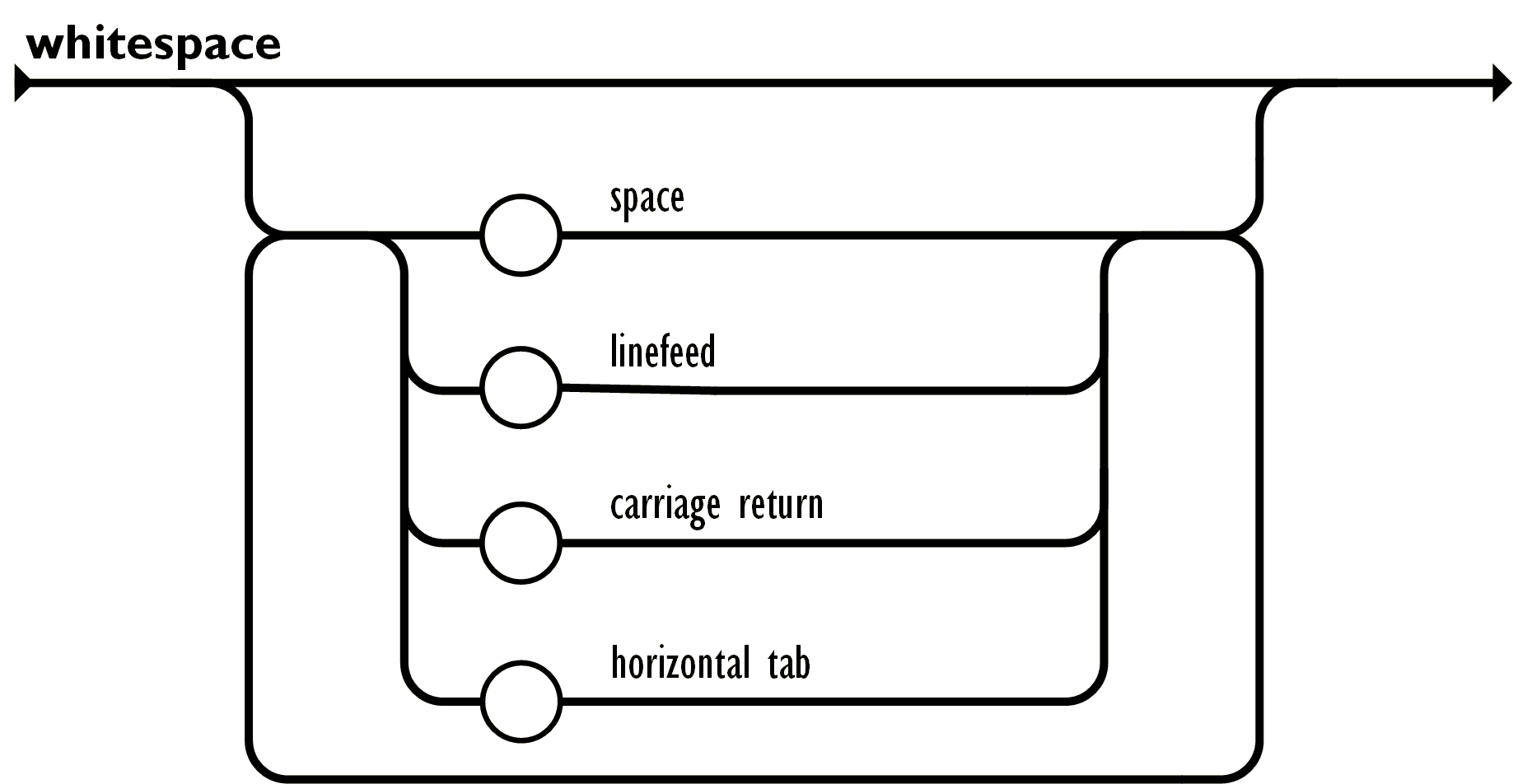 Below we see how whitespace is scanned in JSON. We'll add a lexer for inline
comments
Below we see how whitespace is scanned in JSON. We'll add a lexer for inline
comments //... as well.
const lexer = new pz.Lexer<JsonToken>({
"true": JsonToken.True,
"false": JsonToken.False,
"null": JsonToken.Null,
"\\{": JsonToken.LeftBrace,
"\\}": JsonToken.RightBrace,
"\\[": JsonToken.LeftBracket,
"\\]": JsonToken.RightBracket,
",": JsonToken.Comma,
":": JsonToken.Colon,
"-?(?:[1-9]\\d+|\\d(?!\\d))(?:\\.\\d+)?(?:[eE][+-]?\\d+)?": JsonToken.Number,
'"(?:(?:(?!["\\\\])[\\u{0020}-\\u{ffff}])|(?:\\\\(?:["\\\\\\/bnfrt]|(?:u[0-9a-fA-F]{4}))))*"':
JsonToken.String,
"[\\t\\n\\r ]+": JsonToken.Whitespace,
"\\/\\/[^\\n\\r]*": JsonToken.Comment
})
With tokens defined, parsers for terminals are trivial to write. Note how
we map the terminals to JavaScript types. We even cheat a bit, and convert
strings using JSON.parse. We skip the trailing whitespace (including
comments) for each token which makes our other rules simpler.
const comment = pz.token(JsonToken.Comment)
const whitespace = pz.token(JsonToken.Whitespace).or(comment).zeroOrMore()
const number = pz.terminal(JsonToken.Number, "<number>")
.map(t => <any>Number(t.text)).followedBy(whitespace)
const string = pz.terminal(JsonToken.String, "<string>")
.map(t => <any>JSON.parse(t.text)).followedBy(whitespace)
const littrue = pz.terminal(JsonToken.True, "true").map(t => <any>true)
.followedBy(whitespace)
const litfalse = pz.terminal(JsonToken.False, "false").map(t => <any>false)
.followedBy(whitespace)
const litnull = pz.terminal(JsonToken.Null, "null").map(t => <any>null)
.followedBy(whitespace)
const comma = pz.terminal(JsonToken.Comma, ",").followedBy(whitespace)
const colon = pz.terminal(JsonToken.Colon, ":").followedBy(whitespace)
const beginarray = pz.terminal(JsonToken.LeftBracket, "[").followedBy(whitespace)
const endarray = pz.terminal(JsonToken.RightBracket, "]").followedBy(whitespace)
const beginobject = pz.terminal(JsonToken.LeftBrace, "{").followedBy(whitespace)
const endobject = pz.terminal(JsonToken.RightBrace, "}").followedBy(whitespace)
const eof = pz.terminal(JsonToken.EOF, "<end of input>")
Now we can define parsers for nonterminals, the abstract and recursive part
of the grammar. element is a recursive parsing rule that we need to define
later since it depends on other rules. We create a reference cell for it and
then define that multiple elements can be separated by comma.
const element = new pz.Ref<pz.Parser<any, pz.Token<JsonToken>>>()
const elements = pz.forwardRef(element).zeroOrMoreSeparatedBy(comma)
.trace("elements")
An array consists of list of elements separated by comma and bracketed by
[ and ].
const array = elements.bracketedBy(beginarray, endarray).trace("array")
A member (of an object) consist of a string key, a colon, and an element.
The member parser returns a [key, value] pair. The members parses a
list of members separated by commas and returns array of pairs.
const member = string.bind(
s => colon.bind(
c => pz.forwardRef(element).bind(
e => pz.mret(<[string, any]>[s, e]))))
.trace("member")
const members = member.zeroOrMoreSeparatedBy(comma).trace("members")
An object is list of members surrounded by { and }. The parser returns a
JavaScript object which is created by the initObject helper function. It
constructs an object from an array of [key, value] pairs.
const object = members.bracketedBy(beginobject, endobject)
.map(ms => pz.initObject(ms)).trace("object")
Now we can define the element rule. It chooses the next parser to be
applied based on a lookahead token. If it is a left brace or bracket, we
parse an object or an array respectively. If it is a primitive element
(string, number, boolean, or null), we jump directly to the correct parser.
This speeds up parsing as we don't need to use the or combinator, which
tries alternative parsers in turn.
element.target = pz.choose(
(token: pz.Token<JsonToken>) => {
switch (token.token) {
case JsonToken.LeftBrace: return object
case JsonToken.LeftBracket: return array
case JsonToken.String: return string
case JsonToken.Number: return number
case JsonToken.True: return littrue
case JsonToken.False: return litfalse
case JsonToken.Null: return litnull
default: return pz.fail<any, pz.Token<JsonToken>>(token.text,
"{", "[", "<string>", "<number>", "true", "false", "null")
}
}).trace("element")
Finally we can define the root parser for JSON. It is just an element
parser preceded by optional whitespace.
const json = whitespace.seq(element.target).followedBy(eof).trace("json")
If you compare the definitions above to the official grammar in json.org, you'll find that they are almost identical. The only difference is that we need to declare the rules bottom-up as you cannot refer to a rule which is not yet defined. Otherwise it is almost mechanical exercise to convert the grammar to Parzec combinators.
First we provide a function that creates a lexer input stream for a JSON string.
export function jsonInput(text: string): pz.ParserInput<pz.Token<JsonToken>> {
return pz.lexerInput<JsonToken>(text, lexer,
new pz.Token(JsonToken.EOF, "<end of input>"));
}
Then we can define a function that takes a string and returns a JS object.
It throws an exception, if parsing fails. So, it works the same way as
JSON.parse.
export function parseJson(text: string): any {
return pz.parse(json, jsonInput(text))
}
